11月23日开始,搜狗搜索引擎蜘蛛疯狂爬站,经过详细查询,其反复对相同页面进行爬取,并带有查询参数,也就是意味着对动态页面进行爬取。阻止查询参数被抓取将有助于确保搜索引擎仅抓取网站的主要 URL,而不会进入原本创建的巨大蜘蛛陷阱。何况这种恶意查询参数,请求量剧增100倍,更是无法容忍。
一开始在搜狗站长平台先对其进行抓取压力调整,毕竟网站并没有那么多的页面,无需这么大量的支柱;接着对 robots.txt 文件进行某些目录的限制,结果等了几天仍旧如此,大量集中的请求访问严重加剧了服务器负担。于是我决定使用极端手段,彻底禁止这些不听话的蜘蛛抓取那些我不想被收录的页面!robots 协议显然还是太温柔了,直接使用 Nginx 对于不想被爬取的页面进行返回404错误或403错误。
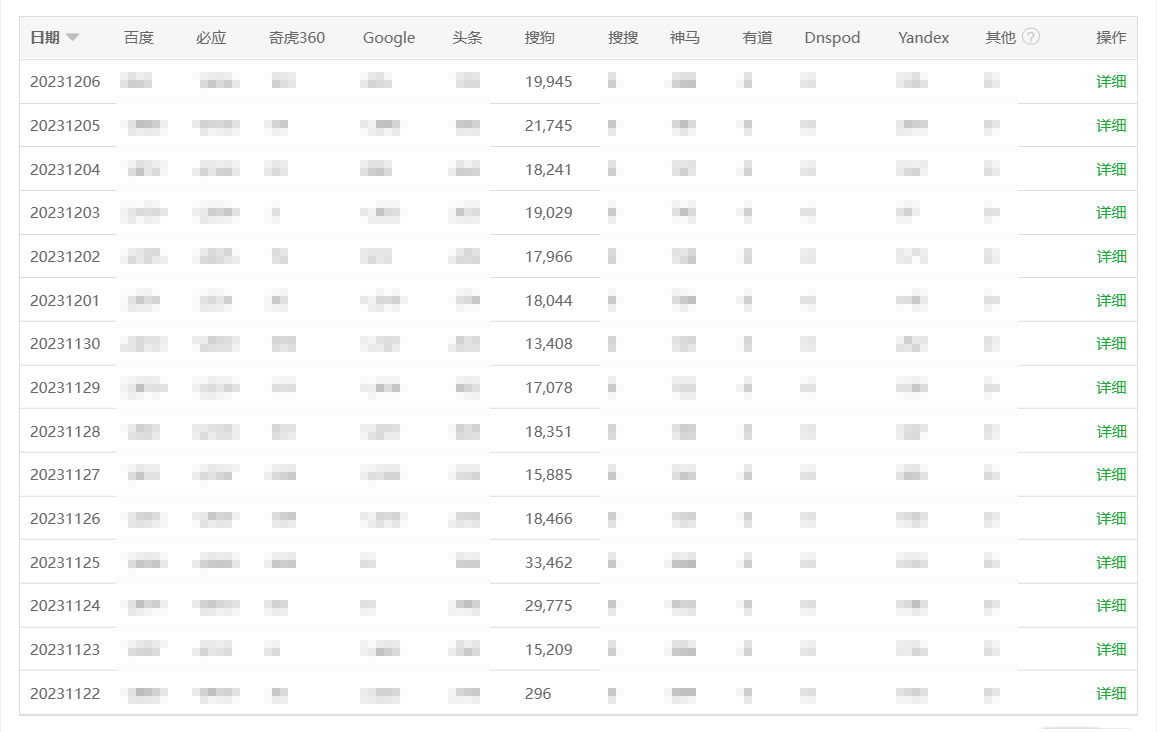
Nginx 拦截规则
由于 WPEXP 使用的是 Nginx,这里就跟大家分享下 Nginx 配置对 SEO 优化。由于宝塔比较方便,这里就用宝塔作为演示,原理是相同的。
[template name=”baota”]
在宝塔的站点配置 → 配置文件,在 Server 模块中的 root 指令之后,添加如下代码:
#### 禁止搜索引擎蜘蛛抓取动态页面和指定路径规则 - https://wpexp.cn/593.html ####
#初始化变量为空
set $deny_spider "";
#如果请求地址中含有需要禁止抓取关键词时,将变量设置为 y:
if ($request_uri ~* "\?replytocom=(\d+)|\?p=(\d+)|/feed|/date|/wp-admin|comment-page-(\d+)|/go") {
set $deny_spider 'y';
}
#如果抓取的 UA 中含有 spider 或 bot 时,继续为变量赋值(通过累加赋值间接实现 nginx 的多重条件判断)
if ($http_user_agent ~* "spider|bot") {
set $deny_spider "${deny_spider}es";
}
#当满足以上 2 个条件时,则返回 404,符合搜索引擎死链标准
if ($deny_spider = 'yes') {
return 403; #如果是删除已收录的,则可以返回 404
break;
}
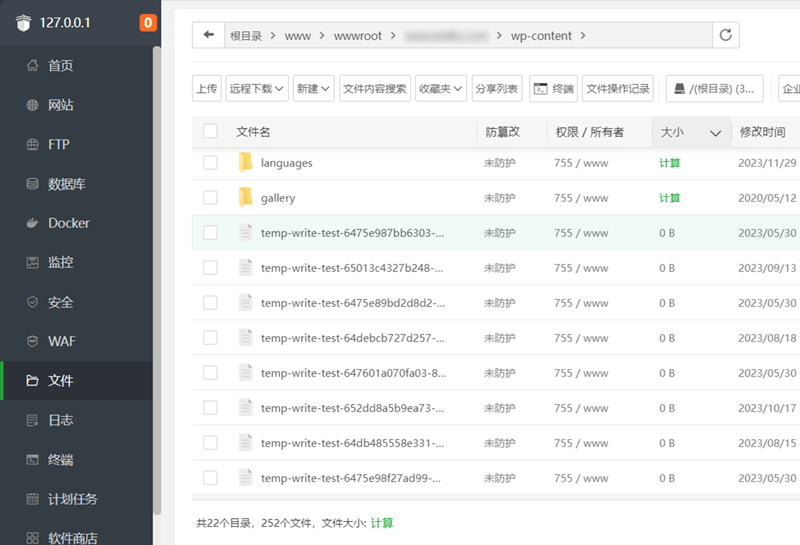
#### 新增规则【结束】 ####具体添加的位置,可以参考下图。
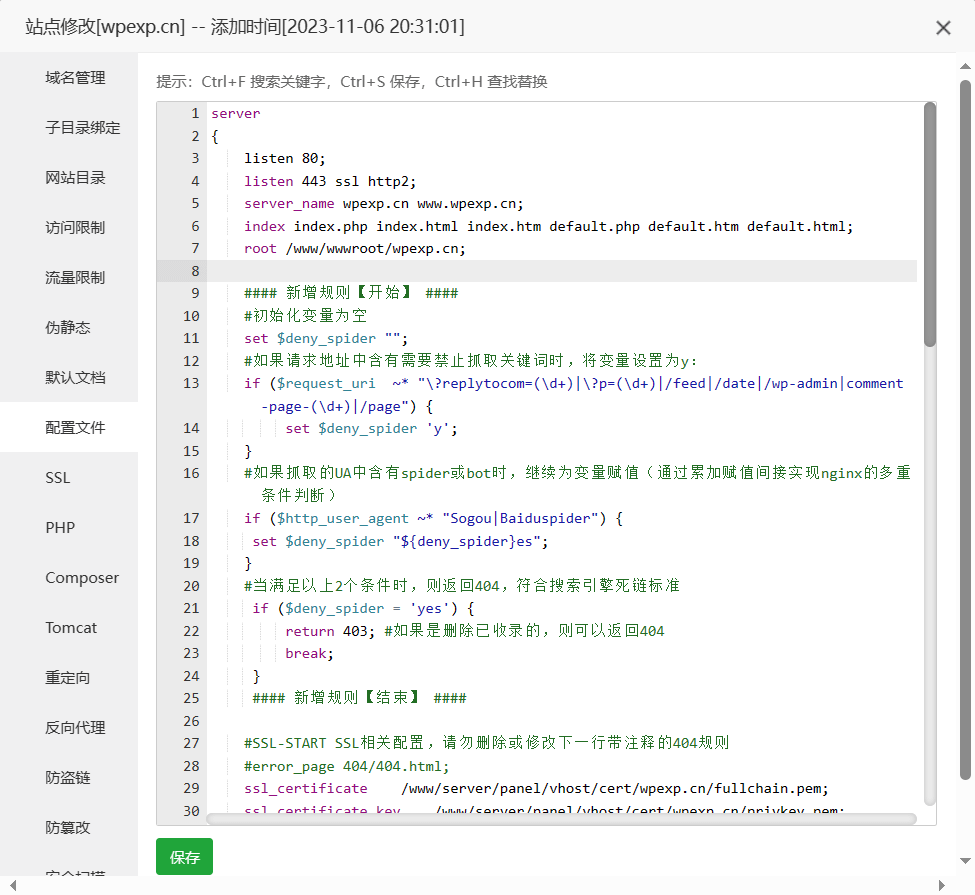
添加好之后保存即可。
拦截效果一览
设置好后,拦截效果杠杠的,所有匹配规则的链接都生效了。
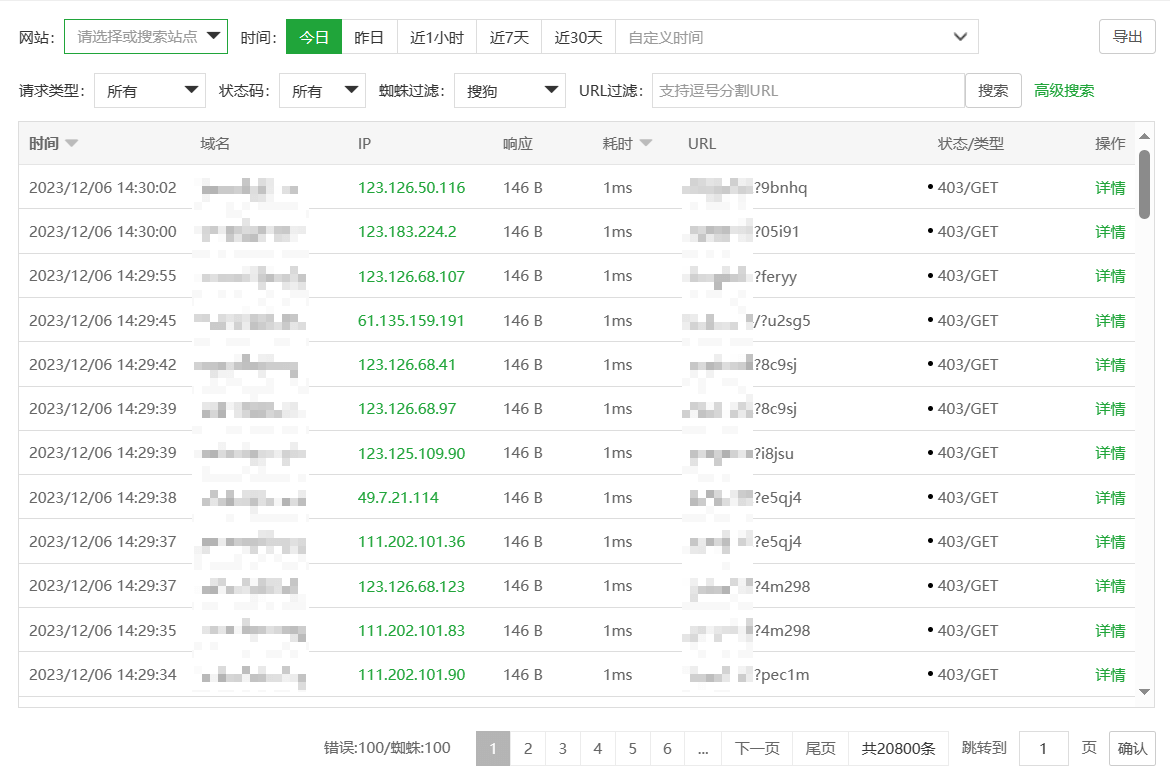
接着使用百度搜索资源平台的抓取诊断测试一下。

好了,今天的分享就到这里。